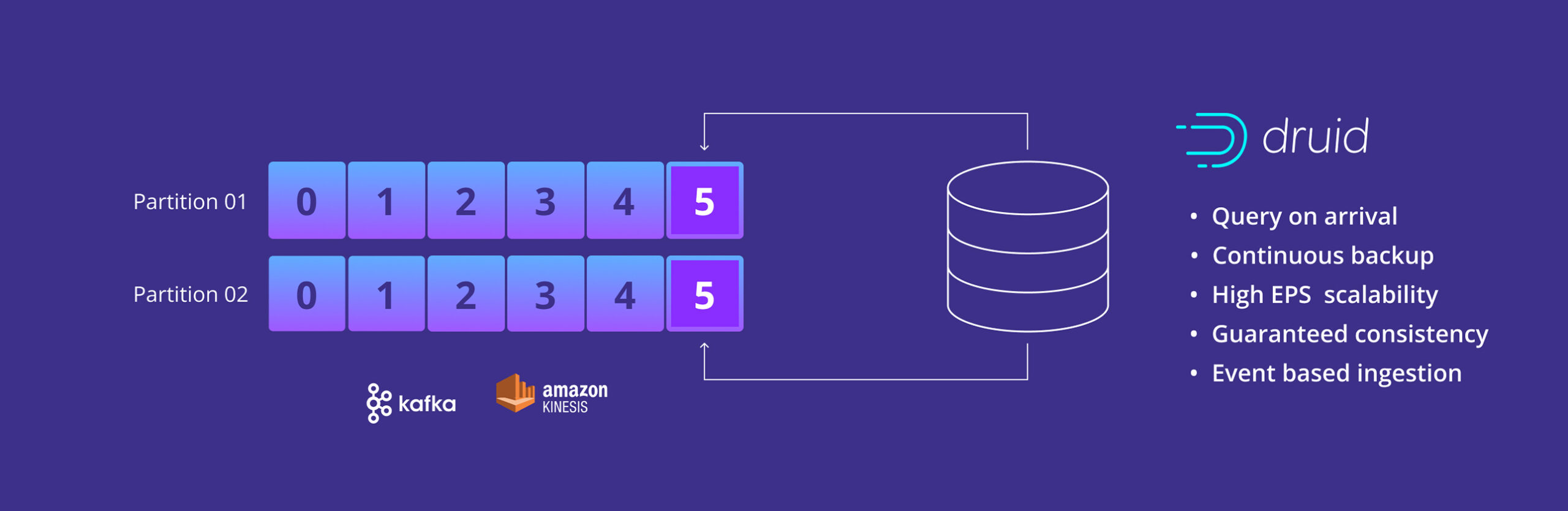
Responds in sub-second
Query millions to trillions of high-dimensional and high-cardinality data with instant results. Our unique architecture makes analytics queries really fast at scale.
Learn more about performance
“We are able to scale datasources to trillions of rows and still achieve query response times in the 10s of milliseconds.”Sr. Software Engineer, Netflix